
IEEE ICASSP 2023 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2023 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
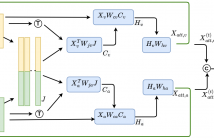
- Read more about Recursive Joint Attention for Audio-Visual Fusion in Regression-Based Emotion Recognition
- Log in to post comments
In video-based emotion recognition (ER), it is important to effectively leverage the complementary relationship among audio (A) and visual (V) modalities, while retaining the intramodal characteristics of individual modalities. In this paper, a recursive joint attention model is proposed along with long short-term memory (LSTM) modules for the fusion of vocal and facial expressions in regression-based ER.
- Categories:
 31 Views
31 Views
- Read more about Improved WiFI-based Respiration Tracking via Contrast Enhancement
- Log in to post comments
Respiratory rate tracking has gained more and more interest in the past few years because of its great potential in exploring different pathological conditions of human beings. Conventional approaches usually require dedicated wearable devices, making them intrusive and unfriendly to users. To tackle the issue, many WiFi-based respiration tracking systems have been proposed because of WiFi’s ubiquity, low-cost, and most importantly, contactlessness. However, most
- Categories:
22 Views
- Read more about QuantPipe: Applying Adaptive Post-Training Quantization for Distributed Transformer Pipelines in Dynamic Edge Environments
- Log in to post comments
Pipeline parallelism has achieved great success in deploying large-scale transformer models in cloud environments, but has received less attention in edge environments. Unlike in cloud scenarios with high-speed and stable network interconnects, dynamic bandwidth in edge systems can degrade distributed pipeline performance. We address this issue withQuantPipe, a communication-efficient distributed edge system that introduces post-training quantization (PTQ) to compress the communicated tensors.
- Categories:
36 Views
- Read more about Multiscale Audio Spectrogram Transformer for Efficient Audio Classification
- Log in to post comments
Audio event has a hierarchical architecture in both time and frequency and can be grouped together to construct more abstract semantic audio classes. In this work, we develop a multiscale audio spectrogram Transformer (MAST) that employs hierarchical representation learning for efficient audio classification. Specifically, MAST employs one-dimensional (and two-dimensional) pooling operators along the time (and frequency domains) in different stages, and progressively reduces the number of tokens and increases the feature dimensions.
- Categories:
45 Views
- Read more about InfoShape: Task-Based Neural Data Shaping via Mutual Information
- Log in to post comments
The use of mutual information as a tool in private data sharing has remained an open challenge due to the difficulty of its estimation in practice. In this paper, we propose InfoShape, a task-based encoder that aims to remove unnecessary sensitive information from training data while maintaining enough relevant information for a particular ML training task. We achieve this goal by utilizing mutual information estimators that are based on neural networks, in order to measure two performance metrics, privacy and utility.
- Categories:
13 Views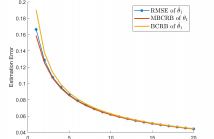
- Read more about Self-supervised learning of audio representations using angular contrastive loss
- Log in to post comments
- Categories:
24 Views
- Read more about Designing Transformer networks for sparse recovery of sequential data using deep unfolding
- Log in to post comments
Deep unfolding models are designed by unrolling an optimization algorithm into a deep learning network. These models have shown faster convergence and higher performance compared to the original optimization algorithms. Additionally, by incorporating domain knowledge from the optimization algorithm, they need much less training data to learn efficient representations. Current deep unfolding networks for sequential sparse recovery consist of recurrent neural networks (RNNs), which leverage the similarity between consecutive signals.
- Categories:
35 Views
- Read more about Mixer: DNN Watermarking using Image Mixup
- Log in to post comments
It is crucial to protect the intellectual property rights of DNN models prior to their deployment. The
DNN should perform two main tasks: its primary task and watermarking task. This paper proposes
a lightweight, reliable, and secure DNN watermarking that attempts to establish strong ties between
these two tasks. The samples triggering the watermarking task are generated using image Mixup
either from training or testing samples. This means that there is an infinity of triggers not limited to the
- Categories:
14 Views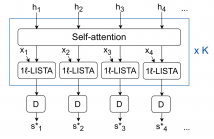
- Read more about Designing Transformer networks for sparse recovery of sequential data using deep unfolding: Presentation
- Log in to post comments
Deep unfolding models are designed by unrolling an optimization algorithm into a deep learning network. These models have shown faster convergence and higher performance compared to the original optimization algorithms. Additionally, by incorporating domain knowledge from the optimization algorithm, they need much less training data to learn efficient representations. Current deep unfolding networks for sequential sparse recovery consist of recurrent neural networks (RNNs), which leverage the similarity between consecutive signals.
- Categories:
30 Views