IEEE ICASSP 2024 - IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The IEEE ICASSP 2024 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
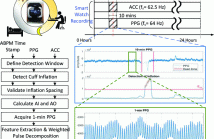
- Read more about MAML-Based 24-Hour Personalized Blood Pressure Estimation from Wrist Photoplethysmography Signals in Free-Living Context
- Log in to post comments
Systolic blood pressure (BP) variability at daytime and nighttime, also known as BP dip, has shown its clinical value in diagnosis and treatment of cardiovascular diseases (CVDs). A model agnostic meta learning (MAML)-based 24-hour personalized approach is proposed in this paper for BP estimation using wrist photoplethysmography (PPG) signals from smart watch in free-living context.
- Categories:
 53 Views
53 Views- Read more about Exploiting spatial attention mechanism for improved depth completion and feature fusion in novel view synthesis
- Log in to post comments
Many image-based rendering (IBR) methods rely on depth estimates obtained from structured light or time-of-flight depth sensors to synthesize novel views from sparse camera networks. However, these estimates often contain missing or noisy regions, resulting in an incorrect mapping between source and target views. This situation makes the fusion process more challenging, as the visual information is misaligned, inconsistent, or missing.
Ban pdf.pdf
- Categories:
20 Views- Read more about A BI-PYRAMID MULTIMODAL FUSION METHOD FOR THE DIAGNOSIS OF BIPOLAR DISORDERS
- Log in to post comments
Previous research on the diagnosis of Bipolar disorder has mainly focused on resting-state functional magnetic resonance imaging. However, their accuracy can not meet the requirements of clinical diagnosis. Efficient multimodal fusion strategies have great potential for applications in multimodal data and can further improve the performance of medical diagnosis models. In this work, we utilize both sMRI and fMRI data and propose a novel multimodal diagnosis model for bipolar disorder.
- Categories:
16 Views- Read more about A Flexible Framework for Expectation Maximization-Based MIMO System Identification for Time-Variant Linear Acoustic Systems
- Log in to post comments
Quasi-continuous system identification of time-variant linear acoustic systems can be applied in various audio signal processing applications when numerous acoustic transfer functions must be measured. A prominent application is measuring head-related transfer functions. We treat the underlying multiple-input-multiple-output (MIMO) system identification problem in a state-space model as a joint estimation problem for states, representing impulse responses, and state-space model parameters using the expectation maximization (EM) algorithm.
- Categories:
31 Views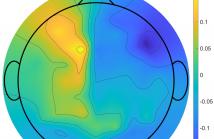
- Read more about Paper
- Log in to post comments
Clusters of neurons generate electrical signals which propagate in all directions through brain tissue, skull, and scalp of different conductivity. Measuring these signals with electroencephalography (EEG) sensors placed on the scalp results in noisy data. This can have severe impact on estimation, such as, source localization and temporal response functions (TRFs). We hypothesize that some of the noise is due to a Wiener-structured signal propagation with both linear and nonlinear components.
- Categories:
27 Views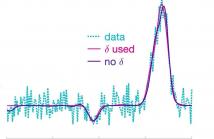
- Read more about Poster: Reversible Jump Markov chain Monte Carlo for Pulse Fitting
- Log in to post comments
This paper proposes a reversible jump Markov chain Monte Carlo method that provides efficient inference for the general problem of pulse fitting. In particular, it minimises the potential of an adopted parametric model overfitting to the (noisy) data via the inclusion of a peak proximity parameter. This facilitates learning a more representative underlying model and significantly reduces the computational cost. Synthetic and real data are used to demonstrate the efficacy of the introduced Bayesian technique.
Contact: afg30@cam.ac.uk
- Categories:
33 Views- Read more about Contextual Human Object Interaction Understanding From Pre-Trained Large Language Model
- Log in to post comments
Existing human object interaction (HOI) detection methods have introduced zero-shot learning techniques to recognize unseen interactions, but they still have limitations in understanding context information and comprehensive reasoning. To overcome these limitations, we propose a novel HOI learning framework, ContextHOI, which serves as an effective contextual HOI detector to enhance contextual understanding and zero-shot reasoning ability. The main contributions of the proposed ContextHOI are a novel context-mining decoder and a powerful interaction reasoning large language model (LLM).
- Categories:
21 Views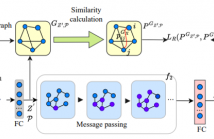
- Read more about Deep Manifold Transformation for Protein Representation Learning
- Log in to post comments
Protein representation learning is critical in various tasks in biology, such as drug design and protein structure or function prediction, which has primarily benefited from protein language models and graph neural networks. These models can capture intrinsic patterns from protein sequences and structures through masking and task-related losses. However, the learned protein representations are usually not well optimized, leading to performance degradation due to limited data, difficulty adapting to new tasks, etc.
- Categories:
56 Views
- Read more about Adaptive Multi-Exposure Fusion for Enhanced Neural Radiance Fields
- Log in to post comments
Neural Radiance Fields (NeRF) have revolutionized 3D scene modeling and rendering. However, their performance dips when handling images with diverse exposure levels, mainly due to the intricate luminance dynamics. Addressing this, we present an innovative method that proficiently models and renders images across a spectrum of exposure conditions. Our approach utilizes an unsupervised classifier-generator structure for HDR fusion, significantly enhancing NeRF's ability to comprehend and adjust to light variations, leading to the generation of images with appropriate brightness.
- Categories:
53 Views- Read more about PRE-TRAINED ACOUSTIC-AND-TEXTUAL MODELING FOR END-TO-END SPEECH-TO-TEXT TRANSLATION
- Log in to post comments
End-to-end paradigm has aroused more and more interests and attention for improving speech-to-text translation (ST) recently. Existing end-to-end models mainly attributes and attempts to address the problem of modeling burden and data scarcity, while always fail to maintain both cross-modal and cross-lingual mapping well at the same time.
- Categories:
33 Views