- Human Spoken Language Acquisition, Development and Learning (SLP-LADL)
- Language Modeling, for Speech and SLP (SLP-LANG)
- Machine Translation of Speech (SLP-SSMT)
- Speech Data Mining (SLP-DM)
- Speech Retrieval (SLP-IR)
- Spoken and Multimodal Dialog Systems and Applications (SLP-SMMD)
- Spoken language resources and annotation (SLP-REAN)
- Spoken Language Understanding (SLP-UNDE)
- Read more about Weighted Sampling For Masked Language Modeling
- Log in to post comments
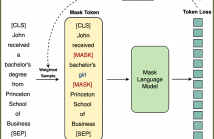
Masked Language Modeling (MLM) is widely used to pretrain language models. The standard random masking strategy in MLM causes the pre-trained language models (PLMs) to be biased towards high-frequency tokens. Representation learning of rare tokens is poor and PLMs have limited performance on downstream tasks. To alleviate this frequency bias issue, we propose two simple and effective Weighted Sampling strategies for masking tokens based on token frequency and training loss. We apply these two strategies to BERT and obtain Weighted-Sampled BERT (WSBERT).
- Categories:
 38 Views
38 Views
- Read more about End-to-end Keyword Spotting using Neural Architecture Search and Quantization
- Log in to post comments
This paper introduces neural architecture search (NAS) for the automatic discovery of end-to-end keyword spotting (KWS) models in limited resource environments. We employ a differentiable NAS approach to optimize the structure of convolutional neural networks (CNNs) operating on raw audio waveforms. After a suitable KWS model is found with NAS, we conduct quantization of weights and activations to reduce the memory footprint. We conduct extensive experiments on the Google speech commands dataset.
icassp_2022_poster.pdf
- Categories:
12 Views

- Read more about LEARNING TO SELECT CONTEXT IN A HIERARCHICAL AND GLOBAL PERSPECTIVE FOR OPEN-DOMAIN DIALOGUE GENERATION
- Log in to post comments
- Categories:
22 Views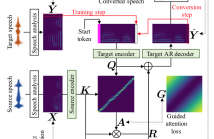
- Read more about AttS2S-VC: Sequence-to-Sequence Voice Conversion with Attention and Context Preservation Mechanisms
- Log in to post comments
This paper describes a method based on a sequence-to-sequence learning (Seq2Seq) with attention and context preservation mechanism for voice conversion (VC) tasks. Seq2Seq has been outstanding at numerous tasks involving sequence modeling such as speech synthesis and recognition, machine translation, and image captioning.
- Categories:
75 Views
- Categories:
23 Views
- Read more about End-to-End Anchored Speech Recognition
- Log in to post comments
Voice-controlled house-hold devices, like Amazon Echo or Google Home, face the problem of performing speech recognition of device- directed speech in the presence of interfering background speech, i.e., background noise and interfering speech from another person or media device in proximity need to be ignored. We propose two end-to-end models to tackle this problem with information extracted from the “anchored segment”.
- Categories:
126 Views
- Read more about Robust Spoken Language Understanding with unsupervised ASR-error adaptation
- Log in to post comments
Robustness to errors produced by automatic speech recognition (ASR) is essential for Spoken Language Understanding (SLU). Traditional robust SLU typically needs ASR hypotheses with semantic annotations for training. However, semantic annotation is very expensive, and the corresponding ASR system may change frequently. Here, we propose a novel unsupervised ASR-error adaptation method, obviating the need of annotated ASR hypotheses.
- Categories:
87 Views
- Read more about DEEP MULTIMODAL LEARNING FOR EMOTION RECOGNITION IN SPOKEN LANGUAGE
- Log in to post comments
In this paper, we present a novel deep multimodal framework to predict human emotions based on sentence-level spoken language. Our architecture has two distinctive characteristics. First, it extracts the high-level features from both text and audio via a hybrid deep multimodal structure, which considers the spatial information from text, temporal information from audio, and high-level associations from low-level handcrafted features.
- Categories:
24 Views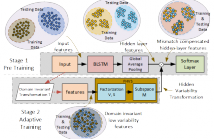
- Read more about FACTORIZED HIDDEN VARIABILITY LEARNING FOR ADAPTATION OF SHORT DURATION LANGUAGE IDENTIFICATION MODELS
- Log in to post comments
Bidirectional long short term memory (BLSTM) recurrent neural networks (RNNs) have recently outperformed other state-of-the-art approaches, such as i-vector and deep neural networks (DNNs) in automatic language identification (LID), particularly when testing with very short utterances (∼3s). Mismatches conditions between training and test data, e.g. speaker, channel, duration and environmental noise, are a major source of performance degradation for LID.
POSTER.pdf
- Categories:
12 Views