
ICASSP is the world's largest and most comprehensive technical conference on signal processing and its applications. It provides a fantastic networking opportunity for like-minded professionals from around the world. ICASSP 2017 conference will feature world-class presentations by internationally renowned speakers and cutting-edge session topics. Visit ICASSP 2017
- Read more about IMPROVED ADVANCED MOTION VECTOR PREDICTION SCHEME FOR SURVEILLANCE VIDEO CODING
- Log in to post comments
- Categories:
 36 Views
36 Views- Read more about REVISITING THE PROBLEM OF AUDIO-BASED HIT SONG PREDICTION USING CONVOLUTIONAL NEURAL NETWORKS
- Log in to post comments
Being able to predict whether a song can be a hit has important applications in the music industry. Although it is true that the popularity of a song can be greatly affected by external factors such as social and commercial influences, to which degree audio features computed from musical signals (whom we regard as internal factors) can predict song popularity is an interesting research question on its own.
icassp2017.pdf
- Categories:
44 Views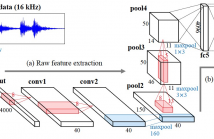
- Read more about Learning Environmental Sounds with End-to-end Convolutional Neural Network
- Log in to post comments
Environmental sound classification (ESC) is usually conducted based on handcrafted features such as the log-mel feature. Meanwhile, end-to-end classification systems perform feature extraction jointly with classification and have achieved success particularly in image classification. In the same manner, if environmental sounds could be directly learned from the raw waveforms, we would be able to extract a new feature effective for classification that could not have been designed by humans, and this new feature could improve the classification performance.
poster1.pdf
- Categories:
49 Views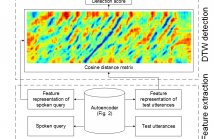
- Read more about Pairwise Learning using Multi-lingual Bottleneck Features for Low-resource Query-by-example Spoken Term Detection
- Log in to post comments
We propose to use a feature representation obtained by pairwise learning in a low-resource language for query-by-example spoken term detection (QbE-STD). We assume that word pairs identified by humans are available in the low-resource target language. The word pairs are parameterized by a multi-lingual bottleneck feature (BNF) extractor that is trained using transcribed data in high-resource languages. The multi-lingual BNFs of the word pairs are used as an initial feature representation to train an autoencoder (AE).
- Categories:
42 Views- Read more about Global Variance in Speech Synthesis with Linear Dynamical Models
- Log in to post comments
GV_LDM.pdf
- Categories:
9 Views- Read more about mbedded Clustering via Robust Orthogonal Least Square Discriminant Analysis
- Log in to post comments
- Categories:
7 Views- Read more about How should we evaluate supervised hashing?
- Log in to post comments
- Categories:
14 Views
- Read more about FULLY COMPLEX DEEP NEURAL NETWORK FOR PHASE-INCORPORATING MONAURAL SOURCE SEPARATION
- Log in to post comments
- Categories:
11 Views- Read more about FULLY COMPLEX DEEP NEURAL NETWORK FOR PHASE-INCORPORATING MONAURAL SOURCE SEPARATION
- Log in to post comments
- Categories:
17 Views