
ICASSP 2021 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2021 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about ICASSP 2021 Poster
- Log in to post comments
This paper investigates the employment of photoplethysmography (PPG) for user authentication systems. Time-stable and user-specific features are developed by stretching the signal, designing a convolutional neural network and performing a variation-stable approach with three score fusions. Two evaluation scenarios are explored, namely single-session and two-sessions.
- Categories:
 177 Views
177 Views
- Categories:
6 Views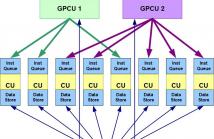
- Read more about SLAP: A Split Latency Adaptive VLIW Pipeline Architecture which enables on-the-fly Variable SIMD Vector Length
- Log in to post comments
Over the last decade the relative latency of access to shared memory by multicore increased as wire resistance dominated latency and low wire density layout pushed multi-port memories farther away from their ports. Various techniques were deployed to improve average memory access latencies, such as speculative pre-fetching and branch-prediction, often leading to high variance in execution time which is unacceptable in real-time systems. Smart DMAs can be used
- Categories:
32 Views
- Read more about ICASSP21 Poster of `Nonnegative Unimodal Matrix Factorization'
- Log in to post comments
We introduce a new Nonnegative Matrix Factorization (NMF) model called Nonnegative Unimodal Matrix Factorization (NuMF), which adds on top of NMF the unimodal condition on the columns of the basis matrix. NuMF finds applications for example in analytical chemistry. We propose a simple but naive brute-force heuristics strategy based on accelerated projected gradient. It is then improved by using multi-grid for which we prove that the restriction operator preserves the unimodality.
- Categories:
14 Views
- Read more about ICASSP21 slide of `Nonnegative Unimodal Matrix Factorization'
- Log in to post comments
We introduce a new Nonnegative Matrix Factorization (NMF) model called Nonnegative Unimodal Matrix Factorization (NuMF), which adds on top of NMF the unimodal condition on the columns of the basis matrix. NuMF finds applications for example in analytical chemistry. We propose a simple but naive brute-force heuristics strategy based on accelerated projected gradient. It is then improved by using multi-grid for which we prove that the restriction operator preserves the unimodality.
- Categories:
25 Views
- Read more about Audio-Visual Speech Inpainting with Deep Learning
- Log in to post comments
In this paper, we present a deep-learning-based framework for audio-visual speech inpainting, i.e. the task of restoring the missing parts of an acoustic speech signal from reliable audio context and uncorrupted visual information. Recent work focuses solely on audio-only methods and they generally aim at inpainting music signals, which show highly different structure than speech. Instead, we inpaint speech signals with gaps ranging from 100 ms to 1600 ms to investigate the contribution that vision can provide for gaps of different duration.
- Categories:
15 Views
- Read more about Audio-Visual Speech Inpainting with Deep Learning
- Log in to post comments
In this paper, we present a deep-learning-based framework for audio-visual speech inpainting, i.e. the task of restoring the missing parts of an acoustic speech signal from reliable audio context and uncorrupted visual information. Recent work focuses solely on audio-only methods and they generally aim at inpainting music signals, which show highly different structure than speech. Instead, we inpaint speech signals with gaps ranging from 100 ms to 1600 ms to investigate the contribution that vision can provide for gaps of different duration.
- Categories:
22 Views
- Read more about SEMI-SUPERVISED FEATURE EMBEDDING FOR DATA SANITIZATION IN REAL-WORLD EVENTS
- Log in to post comments
With the rapid growth of data sharing through social media networks, determining relevant data items concerning a particular subject becomes paramount. We address the issue of establishing which images represent an event of interest through a semi-supervised learning technique. The method learns consistent and shared features related to an event (from a small set of examples) to propagate them to an unlabeled set. We investigate the behavior of five image feature representations considering low- and high-level features and their combinations.
slides_icassp2021.pdf
- Categories:
27 Views
- Read more about A PARTIALLY COLLAPSED GIBBS SAMPLER FOR UNSUPERVISED NONNEGATIVE SPARSE SIGNAL RESTORATION
- Log in to post comments
In this paper the problem of restoration of unsupervised nonnegative sparse signals is addressed in the Bayesian framework. We introduce a new probabilistic hierarchical prior, based on the Generalized Hyperbolic (GH) distribution, which explicitly accounts for sparsity. On the one hand, this new prior allows us to take into account the non-negativity.
- Categories:
11 Views
- Read more about MODELING HOMOPHONE NOISE FOR ROBUST NEURAL MACHINE TRANSLATION
- Log in to post comments
- Categories:
20 Views