
IEEE ICASSP 2023 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2023 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
- Read more about Coherent long-time integration and Bayesian detection with Bernoulli track-before-detect
- Log in to post comments
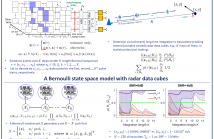
We consider the problem of detecting small and manoeuvring objects with staring array radars. Coherent processing and long-time integration are key to addressing the undesirably low signal-to-noise/background conditions in this scenario and are complicated by the object manoeuvres. We propose a Bayesian solution that builds upon a Bernoulli state space model equipped with the likelihood of the radar data cubes through the radar ambiguity function. Likelihood evaluation in this model corresponds to coherent long-time integration.
- Categories:
 75 Views
75 Views
- Read more about ICASSP 2023 AUDITORY EEG DECODING CHALLENGE
- Log in to post comments
- Categories:
157 Views
- Read more about Gridless 3D Recovery of Image Sources from Room Impulse Responses
- Log in to post comments
Given a sound field generated by a sparse distribution of impulse image sources, can the continuous 3D positions and amplitudes of these sources be recovered from discrete, band-limited measurements of the field at a finite set of locations, e.g. , a multichannel room impulse response? Borrowing from recent advances in super-resolution imaging, it is shown that this non-linear, non-convex inverse problem can be efficiently relaxed into a convex linear inverse problem over the space of Radon measures in R^3 .
poster.pdf
- Categories:
28 Views
- Read more about Poster
- Log in to post comments
Listening to spoken content often requires modifying the speech rate while preserving the timbre and pitch of the speaker. To date, advanced signal processing techniques are used to address this task, but it still remains a challenge to maintain a high speech quality at all time-scales. Inspired by the success of speech generation using Generative Adversarial Networks (GANs), we propose a novel unsupervised learning algorithm for time-scale modification (TSM) of speech, called ScalerGAN. The model is trained using a set of speech utterances, where no time-scales are provided.
- Categories:
31 Views
- Read more about Image source method based on the directional impulse responses
- Log in to post comments
This paper presents the image source method for simulating the observed signals in the time-domain on the boundary of a spherical listening region. A wideband approach is used where all derivations are in the time-domain. The source emits a sequence of spherical wave fronts whose amplitudes could be related to the far-field directional impulse responses of a loudspeaker. Geometric methods are extensively used to model the observed signals. The spherical harmonic coefficients of the observed signals are also derived.
- Categories:
28 Views
- Read more about Efficient Large-scale Audio Tagging via Transformer-to-CNN Knowledge Distillation
- Log in to post comments
Audio Spectrogram Transformer models rule the field of Audio Tagging, outrunning previously dominating Convolutional Neural Networks (CNNs). Their superiority is based on the ability to scale up and exploit large-scale datasets such as AudioSet. However, Transformers are demanding in terms of model size and computational requirements compared to CNNs. We propose a training procedure for efficient CNNs based on offline Knowledge Distillation (KD) from high-performing yet complex transformers.
- Categories:
34 Views
- Read more about Supervised Hierarchical Clustering Using Graph Neural Networks For Speaker Diarization
- Log in to post comments
- Categories:
325 Views
- Read more about STATISTICAL ANALYSIS OF SPEECH DISORDER SPECIFIC FEATURES TO CHARACTERISE DYSARTHRIA SEVERITY LEVEL
- Log in to post comments
Poor coordination of the speech production subsystems due to any neurological injury or a neuro-degenerative disease leads to dysarthria, a neuro-motor speech disorder. Dysarthric
- Categories:
32 Views
- Read more about Wave-U-Net Discriminator: Fast and Lightweight Discriminator for Generative Adversarial Network-Based Speech Synthesis
- Log in to post comments
This study proposes a Wave-U-Net discriminator, which is a single but expressive discriminator that assesses a waveform in a sample-wise manner with the same resolution as the input signal while extracting multilevel features via an encoder and decoder with skip connections. The experimental results demonstrate that a Wave-U-Net discriminator can be used as an alternative to a typical ensemble of discriminators while maintaining speech quality, reducing the model size, and accelerating the training speed.
- Categories:
32 Views
- Read more about Binary sequence set optimization for CDMA applications via mixed-integer quadratic programming
- Log in to post comments
icassp_poster.pdf
- Categories:
18 Views