- Read more about Blind Room Volume Estimation from Single-Channel Noisy Speech
- Log in to post comments
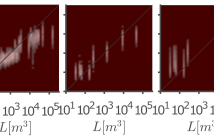
Recent work on acoustic parameter estimation indicates that geometric room volume can be useful for modeling the character of an acoustic environment. However, estimating volume from audio signals remains a challenging problem. Here we propose using a convolutional neural network model to estimate the room volume blindly from reverberant single-channel speech signals in the presence of noise. The model is shown to produce estimates within approximately a factor of two to the true value, for rooms ranging in size from small offices to large concert halls.
- Categories:
 29 Views
29 Views
- Categories:
40 Views
- Read more about DSSLIC: Deep Semantic Segmentation-based Layered Image Compression
- Log in to post comments
We propose a deep semantic segmentation-based layered image compression (DSSLIC) framework in which the segmentation map of the input image is obtained and encoded as the base layer of the bit-stream. Experimental results show that the proposed framework outperforms the H.265/HEVC-based BPG and other codecs in both PSNR and MS-SSIM metrics in RGB domain. Besides, since semantic map is included in the bit-stream, the proposed scheme can facilitate many other tasks such as image search and object-based adaptive image compression.
- Categories:
31 Views
- Read more about Low-cost Measurement of Industrial Shock Signals via Deep Learning Calibration
- Log in to post comments
Special high-end sensors with expensive hardware are usually needed to measure shock signals with high accuracy. In this paper, we show that cheap low-end sensors calibrated by deep neural networks are also capable to measure high-g shocks accurately. Firstly we perform drop shock tests to collect a dataset of shock signals measured by sensors of different fidelity. Secondly, we propose a novel network to effectively learn both the signal peak and overall shape.
- Categories:
16 Views
- Read more about Recurrent Neural Networks with Stochastic Layers for Acoustic Novelty Detection
- Log in to post comments
In this paper, we adapt Recurrent Neural Networks with Stochastic Layers, which are the state-of-the-art for generating text, music and speech, to the problem of acoustic novelty detection. By integrating uncertainty into the hidden states, this type of network is able to learn the distribution of complex sequences. Because the learned distribution can be calculated explicitly in terms of probability, we can evaluate how likely an observation is then detect low-probability events as novel.
- Categories:
5 Views
- Read more about LEARNING TEMPORAL INFORMATION FROM SPATIAL INFORMATION USING CAPSNETS FOR HUMAN ACTION RECOGNITION
- Log in to post comments
Capsule Networks (CapsNets) are recently introduced to overcome some of the shortcomings of traditional Convolutional Neural Networks (CNNs). CapsNets replace neurons in CNNs with vectors to retain spatial relationships among the features. In this paper, we propose a CapsNet architecture that employs individual video frames for human action recognition without explicitly extracting motion information. We also propose weight pooling to reduce the computational complexity and improve the classification accuracy by appropriately removing some of the extracted features.
- Categories:
41 Views
- Read more about Hierarchy-aware Loss Function on a Tree Structured Label Space for Audio Event Detection
- Log in to post comments
The paper introduces a hierarchy-aware loss function in a Deep Neural Network for an audio event detection task that has a bi-level tree structured label space. The goal is not only to improve audio event detection performance at all levels in the label hierarchy, but also to produce better audio embeddings. We exploit the label tree structure to preserve that information in the hierarchy-aware loss function. Two different loss functions are separately employed. First, a triplet loss with probabilistic multi-level batch mining is introduced.
- Categories:
64 Views
The cloud-based speech recognition/API provides developers or enterprises an easy way to create speech-enabled features in their applications. However, sending audios about personal or company internal information to the cloud, raises concerns about the privacy and security issues. The recognition results generated in cloud may also reveal some sensitive information. This paper proposes a deep polynomial network (DPN) that can be applied to the encrypted speech as an acoustic model. It allows clients to send their data in an encrypted form to the cloud to ensure that their data remains confidential, at mean while the DPN can still make frame-level predictions over the encrypted speech and return them in encrypted form. One good property of the DPN is that it can be trained on unencrypted speech features in the traditional way. To keep the cloud away from the raw audio and recognition results, a cloud-local joint decoding framework is also proposed. We demonstrate the effectiveness of model and framework on the Switchboard and Cortana voice assistant tasks with small performance degradation and latency increased comparing with the traditional cloud-based DNNs.
https://ieeexplore.ieee.org/document/8683721
- Categories:
25 Views
- Read more about CONTINUAL LEARNING FOR ANOMALY DETECTION WITH VARIATIONAL AUTOENCODER
- Log in to post comments
- Categories:
94 Views