IEEE ICASSP 2024 - IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The IEEE ICASSP 2024 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.
- Read more about UNIFIED PRETRAINING TARGET BASED CROSS-MODAL VIDEO-MUSIC RETRIEVAL
- Log in to post comments
Background music (BGM) can enhance the video’s emotion and thus make it engaging. However, selecting an appropriate BGM often requires domain knowledge or a deep understanding of the video. This has led to the development of video-music retrieval techniques. Most existing approaches utilize pre-trained video/music feature extractors trained with different target sets to obtain average video/music-level embeddings for cross-modal matching. The drawbacks are two-fold. One is that different target sets for video/music pre-training may cause the generated embeddings difficult to match.
icassp-cbv.pdf
- Categories:
 27 Views
27 Views
- Read more about Computing an Entire Solution Path of a Nonconvexly Regularized Convex Sparse Model
- Log in to post comments
The generalized minimax concave (GMC) penalty is a nonconvex sparse regularizer which can preserve the overall-convexity of the sparse least squares problem. In this paper, we study the solution path of a special but important instance of the GMC model termed the scaled GMC (sGMC) model. We show that despite the nonconvexity of the regularizer, there exists a solution path of the sGMC model which is piecewise linear as a function of the regularization parameter, and we propose an efficient algorithm for computing a solution path of this type.
- Categories:
44 Views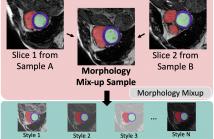
- Read more about MMS: Morphology-mixup Stylized Data Generation for Single Domain Generalization in Medical Image Segmentation
- Log in to post comments
Single-source domain generalization in medical image segmentation is a challenging yet practical task, as domain shift commonly exists across medical datasets.
Previous works have attempted to alleviate this problem through adversarial data augmentation or random-style transformation.
However, these approaches neither fully leverage medical information nor consider the morphological structure alterations.
To address these limitations and enhance the fidelity and diversity of the augmented data,
- Categories:
27 Views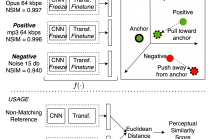
- Read more about NOMAD: Non-Matching Audio Distance
- Log in to post comments
This paper presents NOMAD (Non-Matching Audio Distance), a differentiable perceptual similarity metric that measures the distance of a degraded signal against non-matching references. The proposed method is based on learning deep feature embeddings via a triplet loss guided by the Neurogram Similarity Index Measure (NSIM) to capture degradation intensity. During inference, the similarity score between any two audio samples is computed through Euclidean distance of their embeddings. NOMAD is fully unsupervised and can be used in general perceptual audio tasks for audio analysis e.g.
- Categories:
30 Views- Read more about LEARNING SPATIO-TEMPORAL RELATIONS WITH MULTI-SCALE INTEGRATED PERCEPTION FOR VIDEO ANOMALY DETECTION
- Log in to post comments
In weakly supervised video anomaly detection, it has been verified that anomalies can be biased by background noise. Previous works attempted to focus on local regions to exclude irrelevant information. However, the abnormal events in different scenes vary in size, and current methods struggle to consider local events of different scales concurrently. To this end, we propose a multi-scale integrated perception
ye_poster.pdf
- Categories:
16 Views
- Read more about Exploring Latent Cross-Channel Embedding for Accurate 3D Human Pose Reconstruction in a Diffusion Framework
- Log in to post comments
Monocular 3D human pose estimation poses significant challenges due to the inherent depth ambiguities that arise during the reprojection process from 2D to 3D. Conventional approaches that rely on estimating an over-fit projection matrix struggle to effectively address these challenges and often result in noisy outputs. Recent advancements in diffusion models have shown promise in incorporating structural priors to address reprojection ambiguities.
- Categories:
55 Views- Read more about A Machine-Learning Model for Detecting Depression, Anxiety, and Stress from Speech
- Log in to post comments
Predicting mental health conditions from speech has been widely explored in recent years. Most studies rely on a single sample from each subject to detect indicators of a particular disorder. These studies ignore two important facts: certain mental disorders tend to co-exist, and their severity tends to vary over time.
- Categories:
50 Views
- Read more about Parameter Estimation Procedures for Deep Multi-Frame MVDR Filtering for Single-Microphone Speech Enhancement
- Log in to post comments
Aiming at exploiting temporal correlations across consecutive time frames in the short-time Fourier transform (STFT) domain, multi-frame algorithms for single-microphone speech enhancement have been proposed, which apply a complex- valued filter to the noisy STFT coefficients. Typically, the multi-frame filter coefficients are either estimated directly using deep neural networks or a certain filter structure is imposed, e.g., the multi-frame minimum variance distortionless response (MFMVDR) filter structure.
- Categories:
33 Views- Read more about DE NOVO MOLECULE GENERATION WITH GRAPH LATENT DIFFUSION MODEL
- Log in to post comments
De novo generation of molecules is a crucial task in drug discovery. The blossom of deep learning-based generative models, especially diffusion models, has brought forth promising advancements in de novo drug design by finding optimal molecules in a directed manner. However, due to the complexity of chemical space, existing approaches can only generate extremely small molecules. In this study, we propose a Graph Latent Diffusion Model (GLDM) that operates a diffusion model in the latent space modeled by a pretrained autoencoder.
- Categories:
38 Views
- Read more about Self-supervised Speaker Verification with Adaptive Threshold and Hierarchical Training
- 1 comment
- Log in to post comments
This is a poster material of recent research accepted by IEEE ICASSP 2024.
Title: SELF-SUPERVISED SPEAKER VERIFICATION WITH ADAPTIVE THRESHOLD AND HIERARCHICAL TRAINING
For more inforamation, please check out the publication at IEEE Xplore:
https://ieeexplore.ieee.org/document/10448455
- Categories:
36 Views