
ICASSP 2021 - IEEE International Conference on Acoustics, Speech and Signal Processing is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2021 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

- Read more about PROGRESSIVE MULTI-STAGE FEATURE MIX FOR PERSON RE-IDENTIFICATION
- 1 comment
- Log in to post comments
slides.pdf
- Categories:
 25 Views
25 Views
- Read more about Streaming Multi-Speaker ASR with RNN-T
- Log in to post comments
Recent research shows end-to-end ASR systems can recognize overlapped speech from multiple speakers. However, all published works have assumed no latency constraints during inference, which does not hold for most voice assistant inter- actions. This work focuses on multi-speaker speech recognition based on a recurrent neural network transducer (RNN-T) that has been shown to provide high recognition accuracy at a low latency online recognition regime.
- Categories:
36 Views
Reverberation time, T60, directly influences the amount of reverberation
in a signal, and its direct estimation may help with
dereverberation. Traditionally, T60 estimation has been done
using signal processing or probabilistic approaches, until recently
where deep-learning approaches have been developed.
Unfortunately, the appropriate loss function for training the
network has not been adequately determined. In this paper,
we propose a composite classification- and regression-based
- Categories:
26 Views
- Read more about OAS-Net: Occlusion Aware Sampling Network for Accurate Optical Flow
- Log in to post comments
OASNet_poster.pdf
- Categories:
16 Views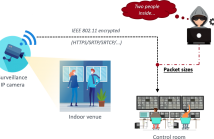
- Read more about Looking through Walls: Inferring Scenes from Video-Surveillance Encrypted Traffic
- Log in to post comments
Nowadays living environments are characterized by networks of inter-connected sensing devices that accomplish different tasks, e.g., video-surveillance of an environment by a network of CCTV cameras. A malicious user could gather sensitive details on people’s activities by eavesdropping the exchanged data packets. To overcome this problem,video streams are protected by encryption systems, but even secured channels may still leak some information.
- Categories:
29 Views
- Read more about Parameter Identifiability of Spatial-Smoothing-Based Bistatic MIMO Radar
- Log in to post comments
Diversity smoothing has been widely developed for angle estimation with bistatic multiple input multiple output (MIMO) radar in the presence of coherent targets, the parameter identifiability of which is an important issue. In this paper, we are devoted to establishing more accurate conditions by studying the positive definiteness of smoothed target covariance matrix. The antenna numbers of transmit and receive arrays are derived as functions of the target number and target structure. We show that the new results improve upon previous ones and recover them in special cases.
- Categories:
22 Views
We propose a generalized thinned coprime array by introducing the flexible inter-element spacings, where the conventional one can be seen as a special case. We derive closed-form expression for the range of consecutive lags, written as the functions of the antenna numbers and inter-element spacings. We show that, after optimization, the proposed array can achieve more consecutive lags than the other coprime arrays. In particular, the optimized results also provide the minimum number of antenna pairs with small separation.
- Categories:
15 Views
- Read more about Fusing Information Streams in End-to-End Audio-Visual Speech Recognition
- Log in to post comments
End-to-end acoustic speech recognition has quickly gained widespread popularity and shows promising results in many studies. Specifically the joint transformer/CTC model provides very good performance in many tasks. However, under noisy and distorted conditions, the performance still degrades notably. While audio-visual speech recognition can significantly improve the recognition rate of end-to-end models in such poor conditions, it is not obvious how to best utilize any available information on acoustic and visual signal quality and reliability in these models.
- Categories:
13 Views
- Read more about Communication Over Block Fading Channels - An Algorithmic Perspective on Optimal Transmission Schemes
- Log in to post comments
Wireless channels are considered that change over time but remain constant for a certain (coherence) period. This behavior is perfectly captured by block fading channels and affects the performance of the corresponding wireless communication systems. Desired closed-form characterizations of optimal transmission schemes remain unknown in many cases. This paper approaches this issue from a fundamental, algorithmic point of view by studying whether or not it is in principle possible to construct or find such optimal transmission
- Categories:
33 Views
We investigate a set of techniques for RNN Transducers (RNN-Ts) that were instrumental in lowering the word error rate on three different tasks (Switchboard 300 hours, conversational Spanish 780 hours and conversational Italian 900 hours). The techniques pertain to architectural changes, speaker adaptation, language model fusion, model combination and general training recipe. First, we introduce a novel multiplicative integration of the encoder and prediction network vectors in the joint network (as opposed to additive).
- Categories:
13 Views