
ICASSP is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The ICASSP 2020 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit website.

We propose a general projection-free metric learning framework, where the minimization objective $\min_{\M \in \cS} Q(\M)$ is a convex differentiable function of the metric matrix $\M$, and $\M$ resides in the set $\cS$ of generalized graph Laplacian matrices for connected graphs with positive edge weights and node degrees.
Unlike low-rank metric matrices common in the literature, $\cS$ includes the important positive-diagonal-only matrices as a special case in the limit.
- Categories:
 29 Views
29 Views
This demo will showcase our video-to-audio model which attempts to reconstruct speech from short videos of spoken statements. Our model does so in a completely end-to-end manner where raw audio is generated based on the input video. This approach bypasses the need for separate lip-reading and text-to-speech models. The advantage of such an approach is that it does not require large transcribed datasets and it is not based on intermediate representations like text which remove any intonation and emotional content from the speech.
- Categories:
106 Views
- Read more about IMPROVING CROSS-DATASET PERFORMANCE OF FACE PRESENTATION ATTACK DETECTION SYSTEMS USING FACE RECOGNITION DATASETS
- Log in to post comments
Presentation attack detection (PAD) is now considered critically important for any face-recognition (FR) based access-control system. Current deep-learning based PAD systems show excellent performance when they are tested in intra-dataset scenarios. Under cross-dataset evaluation the performance of these PAD systems drops significantly. This lack of generalization is attributed to domain-shift. Here, we propose a novel PAD method that leverages the large variability present in FR datasets to induce invariance to factors that cause domain-shift.
- Categories:
20 Views
- Read more about DOMAIN ADAPTATION FOR GENERALIZATION OF FACE PRESENTATION ATTACK DETECTION IN MOBILE SETTINGS WITH MINIMAL INFORMATION
- Log in to post comments
With face-recognition (FR) increasingly replacing fingerprint sensors for user-authentication on mobile devices, presentation attacks (PA) have emerged as the single most significant hurdle for manufacturers of FR systems. Current machine-learning based presentation attack detection (PAD) systems, trained in a data-driven fashion, show excellent performance when evaluated in intra-dataset scenarios. Their performance typically degrades significantly in cross-dataset evaluations. This lack of generalization in current PAD systems makes them unsuitable for deployment in real-world scenarios.
- Categories:
34 Views
- Read more about Signal Sensing and Reconstruction Paradigms for a Novel Multi-source Static Computed Tomography System
- Log in to post comments
Conventional Computed Tomography (CT) systems use a single X-ray source and an arc of detectors mounted on a rotating gantry to acquire a set of projection data. Novel CT systems are now being pioneered in which a complete ring of distributed X-ray sources and detectors are electronically turned on and off, without any mechanical motion, to acquire a set of projections for tomographic reconstruction. This paper discusses new sensing and reconstruction paradigms enabled by this new CT architecture.
- Categories:
81 Views
- Read more about ICASSP 2020 Presentation Poster Slides
- Log in to post comments
ONE-SHOT VOICE CONVERSION USING STAR-GAN
- Categories:
820 Views
- Read more about Sparse Beamspace Equalization for Massive MU-MIMO mmWave Systems
- Log in to post comments
- Categories:
25 Views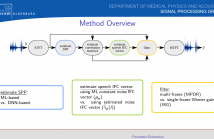
- Read more about DNN-Based Speech Presence Probability Estimation for Multi-Frame Single-Microphone Speech Enhancement
- Log in to post comments
Multi-frame approaches for single-microphone speech enhancement, e.g., the multi-frame minimum-power-distortionless-response (MFMPDR) filter, are able to exploit speech correlations across neighboring time frames. In contrast to single-frame approaches such as the Wiener gain, it has been shown that multi-frame approaches achieve a substantial noise reduction with hardly any speech distortion, provided that an accurate estimate of the correlation matrices and especially the speech interframe correlation (IFC) vector is available.
- Categories:
65 Views
- Read more about SEQUENCE-TO-SUBSEQUENCE LEARNING WITH CONDITIONAL GAN FOR POWER DISAGGREGATION
- Log in to post comments
Non-intrusive load monitoring (a.k.a. power disaggregation) refers to identifying and extracting the consumption patterns of individual appliances from the mains which records the whole-house energy consumption. Recently, deep learning has been shown to be a promising method to solve this problem and many approaches based on it have been proposed.
- Categories:
157 Views
- Read more about Time-Frequency Feature Decomposition Based on Sound Duration for Acoustic Scene Classification
- Log in to post comments
- Categories:
32 Views