- Bayesian learning; Bayesian signal processing (MLR-BAYL)
- Bounds on performance (MLR-PERF)
- Applications in Systems Biology (MLR-SYSB)
- Applications in Music and Audio Processing (MLR-MUSI)
- Applications in Data Fusion (MLR-FUSI)
- Cognitive information processing (MLR-COGP)
- Distributed and Cooperative Learning (MLR-DIST)
- Learning theory and algorithms (MLR-LEAR)
- Neural network learning (MLR-NNLR)
- Information-theoretic learning (MLR-INFO)
- Independent component analysis (MLR-ICAN)
- Graphical and kernel methods (MLR-GRKN)
- Other applications of machine learning (MLR-APPL)
- Pattern recognition and classification (MLR-PATT)
- Source separation (MLR-SSEP)
- Sequential learning; sequential decision methods (MLR-SLER)

- Read more about Deep Reinforcement Learning Based Energy Beamforming for Powering Sensor Networks
- 1 comment
- Log in to post comments
We focus on a wireless sensor network powered with an energy beacon, where sensors send their measurements to the sink using the harvested energy. The aim of the system is to estimate an unknown signal over the area of interest as accurately as possible. We investigate optimal energy beamforming at the energy beacon and optimal transmit power allocation at the sensors under non-linear energy harvesting models. We use a deep reinforcement learning (RL) based approach where multi-layer neural networks are utilized.
- Categories:
 102 Views
102 Views
- Read more about DYNAMIC SYSTEM IDENTIFICATION FOR GUIDANCE OF STIMULATION PARAMETERS IN HAPTIC SIMULATION ENVIRONMENTS
- Log in to post comments
- Categories:
38 Views
- Read more about Efficient Parameter Estimation for Semi-Continuous Data: An Application to Independent Component Analysis
- Log in to post comments
Semi-continuous data have a point mass at zero and are continuous with positive support. Such data arise naturally in several real-life situations like signals in a blind source separation problem, daily rainfall at a location, sales of durable goods among many others. Therefore, efficient estimation of the underlying probability density function is of significant interest.
MLSP_2019.pdf
- Categories:
138 Views
- Read more about VISUALIZING HIGH DIMENSIONAL DYNAMICAL PROCESSES
- Log in to post comments
- Categories:
75 Views
- Read more about Deep Clustering based on a Mixture of Autoencoders
- Log in to post comments
In this paper we propose a Deep Autoencoder Mixture Clustering(DAMIC) algorithm based on a mixture of deep autoencoders whereeach cluster is represented by an autoencoder. A clustering networktransforms the data into another space and then selects one of theclusters. Next, the autoencoder associated with this cluster is usedto reconstruct the data-point. The clustering algorithm jointly learnsthe nonlinear data representation and the set of autoencoders. Theoptimal clustering is found by minimizing the reconstruction loss ofthe mixture of autoencoder network.
- Categories:
102 Views
- Read more about VAE/WGAN-BASED IMAGE REPRESENTATION LEARNING FOR POSE-PRESERVING SEAMLESS IDENTITY REPLACEMENT IN FACIAL IMAGES
- Log in to post comments
We present a novel variational generative adversarial network (VGAN) based on Wasserstein loss to learn a latent representation
from a face image that is invariant to identity but preserves head-pose information. This facilitates synthesis of a realistic face
image with the same head pose as a given input image, but with a different identity. One application of this network is in
privacy-sensitive scenarios; after identity replacement in an image, utility, such as head pose, can still
- Categories:
28 Views
- Read more about Super-resolution of Omnidirectional Images Using Adversarial Learning
- Log in to post comments
An omnidirectional image (ODI) enables viewers to look in every direction from a fixed point through a head-mounted display providing an immersive experience compared to that of a standard image. Designing immersive virtual reality systems with ODIs is challenging as they require high resolution content. In this paper, we study super-resolution for ODIs and propose an improved generative adversarial network based model which is optimized to handle the artifacts obtained in the spherical observational space.
- Categories:
81 Views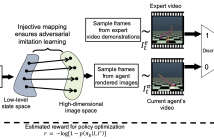
- Read more about Injective State-Image Mapping facilitates Visual Adversarial Imitation Learning
- Log in to post comments
The growing use of virtual autonomous agents in applications like games and entertainment demands better control policies for natural-looking movements and actions. Unlike the conventional approach of hard-coding motion routines, we propose a deep learning method for obtaining control policies by directly mimicking raw video demonstrations. Previous methods in this domain rely on extracting low-dimensional features from expert videos followed by a separate hand-crafted reward estimation step.
mmps_final.pdf
- Categories:
38 Views
- Read more about Single-image rain removal via multi-scale cascading image generation
- Log in to post comments
A novel single-image rain removal method is proposed based on multi-scale cascading image generation (MSCG). In particular, the proposed method consists of an encoder extracting multi-scale features from images and a decoder generating de-rained images with a cascading mechanism. The encoder ensembles the convolution neural networks using the kernels with different sizes, and integrates their outputs across different scales.
- Categories:
41 Views
- Read more about A NOVEL MONOCULAR DISPARITY ESTIMATION NETWORK WITH DOMAIN TRANSFORMATION AND AMBIGUITY LEARNING
- Log in to post comments
Convolutional neural networks (CNN) have shown state-of-the-art results for low-level computer vision problems such as stereo and monocular disparity estimations, but still, have much room to further improve their performance in terms of accuracy, numbers of parameters, etc. Recent works have uncovered the advantages of using an unsupervised scheme to train CNN’s to estimate monocular disparity, where only the relatively-easy-to-obtain stereo images are needed for training.
- Categories:
20 Views