- Bayesian learning; Bayesian signal processing (MLR-BAYL)
- Bounds on performance (MLR-PERF)
- Applications in Systems Biology (MLR-SYSB)
- Applications in Music and Audio Processing (MLR-MUSI)
- Applications in Data Fusion (MLR-FUSI)
- Cognitive information processing (MLR-COGP)
- Distributed and Cooperative Learning (MLR-DIST)
- Learning theory and algorithms (MLR-LEAR)
- Neural network learning (MLR-NNLR)
- Information-theoretic learning (MLR-INFO)
- Independent component analysis (MLR-ICAN)
- Graphical and kernel methods (MLR-GRKN)
- Other applications of machine learning (MLR-APPL)
- Pattern recognition and classification (MLR-PATT)
- Source separation (MLR-SSEP)
- Sequential learning; sequential decision methods (MLR-SLER)
- Read more about Deep Versatile Hyperspectral Reconstruction Model from a Snapshot Measurement with Arbitrary Masks
- 1 comment
- Log in to post comments
Recently, coded aperture snapshot spectral imaging (CASSI) has been actively researched to capture three-dimensional (3D) hyperspectral (HS) images for dynamic scenes, where the optical systems detect a 2D snapshot measurement while a computational algorithm performs the inverse problem for recovering the latent HS cubic data. Benefiting from the powerful modeling capability of the deep convolution neural networks (DCNN), the reconstruction performance of the HS images has been significantly improved.
ID1717.pdf
- Categories:
 23 Views
23 Views
- Read more about RADAR PERCEPTION WITH SCALABLE CONNECTIVE TEMPORAL RELATIONS FOR AUTONOMOUS DRIVING
- Log in to post comments
Due to the noise and low spatial resolution in automotive radar data, exploring temporal relations of learnable features over consecutive 2 radar frames has shown performance gain on downstream tasks (e.g., object detection and tracking) in our previous study. In this paper, we further enhance radar perception by significantly extending the time horizon of temporal relations.
- Categories:
51 Views
- Read more about FINCGAN: A GAN FRAMEWORK OF IMBALANCED NODE CLASSIFICATION ON HETEROGENEOUS GRAPH NEURAL NETWORK
- Log in to post comments
We introduce FincGAN, a GAN framework designed to address the class imbalance in GNNs by enhancing minority sample synthesis and ensuring connectivity with sparsity-aware edge generators.
- Categories:
106 Views- Read more about Improving Continual Learning of Acoustic Scene Classification via Mutual Information Optimization
- Log in to post comments
Continual learning, which aims to incrementally accumulate knowledge, has been an increasingly significant but challenging research topic for deep models that are prone to catastrophic forgetting. In this paper, we propose a novel replay-based continual learning approach in the context of class-incremental learning in acoustic scene classification, to classify audio recordings into an expanding set of classes that characterize the acoustic scenes. Our approach is improving both the modeling and memory selection mechanism via mutual information optimization in continual learning.
MIO_poster.pdf
- Categories:
20 Views
- Read more about USEE: UNIFIED SPEECH ENHANCEMENT AND EDITING WITH CONDITIONAL DIFFUSION MODELS
- Log in to post comments
Speech enhancement aims to improve the quality of speech signals in terms of quality and intelligibility, and speech editing refers to the process of editing the speech according to specific user needs. In this paper, we propose a Unified Speech Enhancement and Editing (uSee) model with conditional diffusion models to handle various tasks at the same time in a generative manner.
- Categories:
16 Views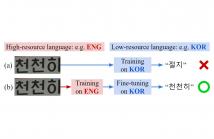
- Read more about CROSS-LINGUAL LEARNING IN MULTILINGUAL SCENE TEXT RECOGNITION
- Log in to post comments
In this paper, we investigate cross-lingual learning (CLL) for multilingual scene text recognition (STR). CLL transfers knowledge from one language to another. We aim to find the condition that exploits knowledge from high-resource languages for improving performance in low-resource languages. To do so, we first examine if two general insights about CLL discussed in previous works are applied to multilingual STR: (1) Joint learning with high- and low-resource languages may reduce performance on low-resource languages, and (2) CLL works best between typologically similar languages.
- Categories:
28 Views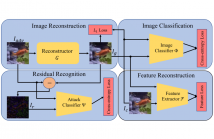
- Read more about Identifying Attack-Specific Signatures in Adversarial Examples
- Log in to post comments
The adversarial attack literature contains numerous algorithms for crafting perturbations which manipulate neural network predictions. Many of these adversarial attacks optimize inputs with the same constraints and have similar downstream impact on the models they attack. In this work, we first show how to reconstruct an adversarial perturbation, namely the difference between an adversarial example and the original natural image, from an adversarial example. Then, we classify reconstructed adversarial perturbations based on the algorithm that generated them.
- Categories:
48 Views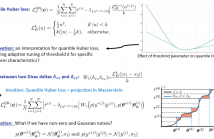
- Read more about A Robust Quantile Huber Loss with Interpretable Parameter Adjustment in Distributional Reinforcement Learning
- Log in to post comments
Distributional Reinforcement Learning (RL) estimates return distribution mainly by learning quantile values via minimizing the quantile Huber loss function, entailing a threshold parameter often selected heuristically or via hyperparameter search, which may not generalize well and can be suboptimal. This paper introduces a generalized quantile Huber loss function derived from Wasserstein distance (WD) calculation between Gaussian distributions, capturing noise in predicted (current) and target (Bellmanupdated) quantile values.
- Categories:
37 Views- Read more about RD-COST REGRESSION SPEED UP TECHNIQUE FOR VVC INTRA BLOCK PARTITIONING
- Log in to post comments
The last standard Versatile Video Codec (VVC) aims to improve the compression efficiency by saving around 50% of bitrate at the same quality compared to its predecessor High Efficiency Video Codec (HEVC). However, this comes with higher encoding complexity mainly due to a much larger number of block splits to be tested on the encoder side.
- Categories:
58 Views- Read more about Exploiting spatial attention mechanism for improved depth completion and feature fusion in novel view synthesis
- Log in to post comments
Many image-based rendering (IBR) methods rely on depth estimates obtained from structured light or time-of-flight depth sensors to synthesize novel views from sparse camera networks. However, these estimates often contain missing or noisy regions, resulting in an incorrect mapping between source and target views. This situation makes the fusion process more challenging, as the visual information is misaligned, inconsistent, or missing.
Ban pdf.pdf
- Categories:
20 Views