- Bayesian learning; Bayesian signal processing (MLR-BAYL)
- Bounds on performance (MLR-PERF)
- Applications in Systems Biology (MLR-SYSB)
- Applications in Music and Audio Processing (MLR-MUSI)
- Applications in Data Fusion (MLR-FUSI)
- Cognitive information processing (MLR-COGP)
- Distributed and Cooperative Learning (MLR-DIST)
- Learning theory and algorithms (MLR-LEAR)
- Neural network learning (MLR-NNLR)
- Information-theoretic learning (MLR-INFO)
- Independent component analysis (MLR-ICAN)
- Graphical and kernel methods (MLR-GRKN)
- Other applications of machine learning (MLR-APPL)
- Pattern recognition and classification (MLR-PATT)
- Source separation (MLR-SSEP)
- Sequential learning; sequential decision methods (MLR-SLER)

- Read more about SD-PINN: Physics Informed Neural Networks for Spatially Dependent PDEs
- Log in to post comments
- Categories:
 27 Views
27 Views
- Read more about Cross-site Generalization for imbalanced epileptic classification
- Log in to post comments
Recently, many studies have been conducted on automated epileptic seizures detection. However, few of these techniques are applied in clinical settings for several reasons. One of them is the imbalanced nature of the seizure detection task. Additionally, the current detection techniques do not really generalize to other patient populations. To address these issues, we present in this paper a hybrid CNN-LSTM model robust to cross-site variability. We investigate the use of data augmentation (DA) methods as an efficient tool to solve imbalanced training problems.
- Categories:
15 Views
- Read more about Cross-site Generalization for imbalanced epileptic classification
- Log in to post comments
Recently, many studies have been conducted on automated epileptic seizures detection. However, few of these techniques are applied in clinical settings for several reasons. One of them is the imbalanced nature of the seizure detection task. Additionally, the current detection techniques do not really generalize to other patient populations. To address these issues, we present in this paper a hybrid CNN-LSTM model robust to cross-site variability. We investigate the use of data augmentation (DA) methods as an efficient tool to solve imbalanced training problems.
- Categories:
10 Views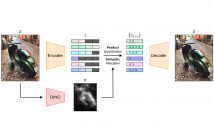
Vector-quantized autoencoders have recently gained interest in image compression, generation and self-supervised learning. However, as a neural compression method, they lack the possibility to allocate a variable number of bits to each image location, e.g. according to the semantic content or local saliency. In this paper, we address this limitation in a simple yet effective way. We adopt a product quantizer (PQ) that produces a set of discrete codes for each image patch rather than a single index.
- Categories:
39 Views
- Read more about Gluformer: Transformer-Based Personalized Glucose Forecasting with Uncertainty Quantification
- Log in to post comments
Deep learning models achieve state-of-the art results in predicting blood glucose trajectories, with a wide range of architectures being proposed. However, the adaptation of such models in clinical practice is slow, largely due to the lack of uncertainty quantification of provided predictions. In this work, we propose to model the future glucose trajectory conditioned on the past as an infinite mixture of basis distributions (i.e., Gaussian, Laplace, etc.).
- Categories:
126 Views
- Read more about ROBUST NONPARAMETRIC DISTRIBUTION FORECAST WITH BACKTEST-BASED BOOTSTRAP AND ADAPTIVE RESIDUAL SELECTION
- Log in to post comments
Distribution forecast can quantify forecast uncertainty and provide various forecast scenarios with their corresponding estimated probabilities. Accurate distribution forecast is crucial for planning - for example when making production capacity or inventory allocation decisions. We propose a practical and robust distribution forecast framework that relies on backtest-based bootstrap and adaptive residual selection.
- Categories:
31 Views
- Read more about Hand Gesture Recognition Using Temporal Convolutions and Attention Mechanism
- Log in to post comments
- Categories:
26 Views
- Read more about PEER COLLABORATIVE LEARNING FOR POLYPHONIC SOUND EVENT DETECTION
- Log in to post comments
This paper describes how semi-supervised learning, called peer collaborative learning (PCL), can be applied to the polyphonic sound event detection (PSED) task, which is one of the tasks in the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge. Many deep learning models have been studied to determine what kind of sound events occur where and for how long in a given audio clip.
- Categories:
21 Views
- Read more about Spatio-Temporal PRRS Epidemic Forecasting via Factorized Deep Generative Modeling
- Log in to post comments
Abstract:
- Categories:
36 Views
In this paper, we focus on learning sparse graphs with a core-periphery structure. We propose a generative model for data associated with core-periphery structured networks to model the dependence of node attributes on core scores of the nodes of a graph through a latent graph structure. Using the proposed model, we jointly infer a sparse graph and nodal core scores that induce dense (sparse) connections in core (respectively, peripheral) parts of the network.
- Categories:
18 Views