IEEE ICASSP 2024 - IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. The IEEE ICASSP 2024 conference will feature world-class presentations by internationally renowned speakers, cutting-edge session topics and provide a fantastic opportunity to network with like-minded professionals from around the world. Visit the website.

- Read more about CRYPTO-MINE: Cryptanalysis via Mutual Information Neural Estimation
- Log in to post comments
The use of Mutual Information (MI) as a measure to evaluate the efficiency of cryptosystems has an extensive history. However, estimating MI between unknown random variables in a high-dimensional space is challenging. Recent advances in machine learning have enabled progress in estimating MI using neural networks. This work presents a novel application of MI estimation in the field of cryptography. We propose applying this methodology directly to estimate the MI between plaintext and ciphertext in a chosen plaintext attack.
CryptoMine.pdf
- Categories:
 24 Views
24 Views
- Read more about Open-Set deepfake detection to fight the unknown
- Log in to post comments
In this paper, we design a new open-set method to detect deepfakes that does not assume information about the techniques behind the deepfakes generation. Contrary to existing methods, which build upon known telltales left by the deepfake creation process, we assume no prior knowledge about the sample generation, thus presenting a method for blind deepfake detection, a necessary step toward true generalization.
- Categories:
20 Views
- Read more about DROPFL: Client Dropout Attacks Against Federated Learning Under Communication Constraints
- Log in to post comments
Federated learning (FL) has emerged as a promising paradigm for decentralized machine learning while preserving data privacy. However, under communication constraints, the standard FL protocol faces the risk of client dropout. Although some research has focused on the risk from the perspectives of communication optimization and privacy protection, it is still challenging to deal with the client dropout issue in dynamic networks, where clients may join or drop the training process at any time.
- Categories:
29 Views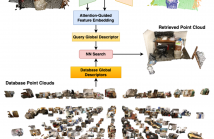
- Read more about AEGIS-Net: Attention-Guided Multi-Level Feature Aggregation for Indoor Place Recognition
- Log in to post comments
We present AEGIS-Net, a novel indoor place recognition model that takes in RGB point clouds and generates global place descriptors by aggregating lower-level color, geometry features and higher-level implicit semantic features. However, rather than simple feature concatenation, self-attention modules are employed to select the most important local features that best describe an indoor place. Our AEGIS-Net is made of a semantic encoder, a semantic decoder and an attention-guided feature embedding.
Poster.pdf
- Categories:
28 Views
- Read more about DATA-SCARCE CONDITION MODELING REQUIRES MODEL-BASED PRIOR REGULARIZATION
- Log in to post comments
In the metallurgical industry, taking measurements during production can be infeasible or undesired, and only the terminated process can be measured. This poses problems for regression models, as the intermediate target values for a time series are hidden in the accumulated end-of-process measurement. The lack of data quality and quantity also often limits the modeling to linear estimators, as neural networks struggle to converge and/or overfit on scarce noisy data.
- Categories:
25 Views
- Read more about Distributed Decision-Making for Community Structured Networks
- Log in to post comments
Traditional social learning frameworks consider environments with a homogeneous state where each agent receives observations conditioned on the same hypothesis. In this work, we study the distributed hypothesis testing problem for graphs with a community structure, assuming that each cluster receives data conditioned on some different true state. This situation arises in many scenarios, such as when sensors are spatially distributed, or when individuals in a social network have differing views or opinions.
- Categories:
22 Views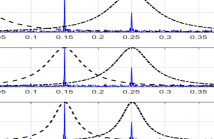
- Read more about Poster for the paper "Dynamic Bandwidth Variational Mode Decomposition"
- Log in to post comments
Signal decomposition techniques aim to break down nonstationary signals into their oscillatory components, serving as a preliminary step in various practical signal processing applications. This has motivated researchers to explore different strategies, yielding several distinct approaches. A wellknown optimization-based method, the Variational Mode Decomposition (VMD), relies on the formulation of an optimization problem utilizing constant-bandwidthWiener filters. However, this poses limitations in constant bandwidth and the need for constituent count.
- Categories:
30 Views
- Read more about Poster - Controllable Prosody Generation With Partial Inputs
- Log in to post comments
Appropriate prosodic choices depend on the context. One approach is for a human-in-the- loop (HitL) to pick the best prosody.
Often there are specific nuanced prosodic choices that convey the intended meaning in a given context.
We propose a system where HitL users can provide any number of prosodic controls. This allows for flexibility and removes the need for redundant (inefficient) work defining the entire prosodic specification.
- Categories:
25 Views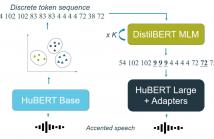
- Read more about Unsupervised Accent Adaptation Through Masked Language Model Correction Of Discrete Self-Supervised Speech Units
- Log in to post comments
Self-supervised pre-trained speech models have strongly improved speech recognition, yet they are still sensitive to domain shifts and accented or atypical speech. Many of these models rely on quantisation or clustering to learn discrete acoustic units. We propose to correct the discovered discrete units for accented speech back to a standard pronunciation in an unsupervised manner. A masked language model is trained on discrete units from a standard accent and iteratively corrects an accented token sequence by masking unexpected cluster sequences and predicting their common variant.
- Categories:
27 Views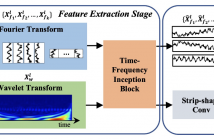
- Read more about WFTNet: Exploiting Global and Local Periodicity in Long-term Time Series Forecasting
- Log in to post comments
Recent CNN and Transformer-based models tried to utilize frequency and periodicity information for long-term time series forecasting. However, most existing work is based on Fourier transform, which cannot capture fine-grained and local frequency structure. In this paper, we propose a Wavelet-Fourier Transform Network (WFTNet) for long-term time series forecasting.
WFTNet.pdf
- Categories:
41 Views