- Bayesian learning; Bayesian signal processing (MLR-BAYL)
- Bounds on performance (MLR-PERF)
- Applications in Systems Biology (MLR-SYSB)
- Applications in Music and Audio Processing (MLR-MUSI)
- Applications in Data Fusion (MLR-FUSI)
- Cognitive information processing (MLR-COGP)
- Distributed and Cooperative Learning (MLR-DIST)
- Learning theory and algorithms (MLR-LEAR)
- Neural network learning (MLR-NNLR)
- Information-theoretic learning (MLR-INFO)
- Independent component analysis (MLR-ICAN)
- Graphical and kernel methods (MLR-GRKN)
- Other applications of machine learning (MLR-APPL)
- Pattern recognition and classification (MLR-PATT)
- Source separation (MLR-SSEP)
- Sequential learning; sequential decision methods (MLR-SLER)

- Read more about OUTLIER REMOVAL FOR ENHANCING KERNEL-BASED CLASSIFIER VIA THE DISCRIMINANT INFORMATION
- Log in to post comments
Pattern recognition on big data can be challenging for kernel machines as the complexity grows with the squared number of training samples. In this work, we overcome this hurdle via the outlying data sample removal pre-processing step. This approach removes less informative data samples and trains the kernel machines only with the remaining data, and hence, directly reduces the complexity by reducing the number of training samples. To enhance the classification performance, the outlier removal process is done such that the discriminant information of the data is mostly intact.
- Categories:
 9 Views
9 Views
- Read more about ADAPTIVE CLUSTERING ALGORITHM FOR COOPERATIVE SPECTRUM SENSING IN MOBILE ENVIRONMENTS
- Log in to post comments
In this work we propose a new adaptive algorithm for coop- erative spectrum sensing in dynamic environments where the channels are time varying. We assume a centralized spectrum sensing procedure based on the soft fusion of the signal energy levels measured at the sensors. The detection problem is posed as a composite hypothesis testing problem. The unknown pa- rameters are estimated by means of an adaptive clustering al- gorithm that operates over the most recent energy estimates re- ported by the sensors to the fusion center.
poster.pdf
- Categories:
17 Views
- Read more about Cross-Modality Distillation: A Case for Conditional Generative Adversarial Networks
- Log in to post comments
In this paper, we propose to use a Conditional Generative Adversarial Network (CGAN) for distilling (i.e. transferring) knowledge from sensor data and enhancing low-resolution target detection. In unconstrained surveillance settings, sensor measurements are often noisy, degraded, corrupted, and even missing/absent, thereby presenting a significant problem for multi-modal fusion. We therefore specifically tackle the problem of a missing modality in our attempt to propose an algorithm
- Categories:
58 Views
- Read more about DIRECTLY SOLVING THE ORIGINAL RATIOCUT PROBLEM FOR EFFECTIVE DATA CLUSTERING
- Log in to post comments
- Categories:
29 Views
- Read more about Regressing Kernel Dictionary Learning
- Log in to post comments
In this paper, we present a kernelized dictionary learning framework for carrying out regression to model signals having a complex non-linear nature. A joint optimization is carried out where the regression weights are learnt together with the dictionary and coefficients. Relevant formulation and dictionary building steps are provided. To demonstrate the effectiveness of the proposed technique, elaborate experimental results using different real-life datasets are presented.
Poster_v31.pdf
- Categories:
23 Views
- Read more about LOCALITY-PRESERVING COMPLEX-VALUED GAUSSIAN PROCESS LATENT VARIABLE MODEL FOR ROBUST FACE RECOGNITION
- Log in to post comments
- Categories:
4 Views
- Read more about Discriminative Probabilistic Framework for Generalized Multi-Instance Learning
- Log in to post comments
Multiple-instance learning is a framework for learning from data consisting of bags of instances labeled at the bag level. A common assumption in multi-instance learning is that a bag label is positive if and only if at least one instance in the bag is positive. In practice, this assumption may be violated. For example, experts may provide a noisy label to a bag consisting of many instances, to reduce labeling time.
- Categories:
29 Views
We propose a novel adversarial multi-task learning scheme, aiming at actively curtailing the inter-talker feature variability while maximizing its senone discriminability so as to enhance the performance of a deep neural network (DNN) based ASR system. We call the scheme speaker-invariant training (SIT). In SIT, a DNN acoustic model and a speaker classifier network are jointly optimized to minimize the senone (tied triphone state) classification loss, and simultaneously mini-maximize the speaker classification loss.
- Categories:
25 Views
- Read more about Adversarial Teacher-Student Learning for Unsupervised Adaptation
- Log in to post comments
The teacher-student (T/S) learning has been shown effective in unsupervised domain adaptation ts_adapt. It is a form of transfer learning, not in terms of the transfer of recognition decisions, but the knowledge of posteriori probabilities in the source domain as evaluated by the teacher model. It learns to handle the speaker and environment variability inherent in and restricted to the speech signal in the target domain without proactively addressing the robustness to other likely conditions. Performance degradation may thus ensue.
- Categories:
39 Views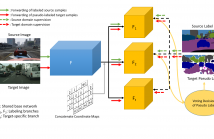
- Read more about A Fully Convolutional Tri-branch Network (FCTN) For Domain Adaptation
- Log in to post comments
A domain adaptation method for urban scene segmentation is proposed in this work. We develop a fully convolutional tri-branch network, where two branches assign pseudo labels to images in the unlabeled target domain while the third branch is trained with supervision based on images in the pseudo-labeled target domain. The re-labeling and re-training processes alternate. With this design, the tri-branch network learns target-specific discriminative representations progressively and, as a result, the cross-domain capability of the segmenter improves.
- Categories:
19 Views